
Festival of Science, Scholarship, and Creativity 2023
Festival of Science, Scholarship, and Creativity was held April 28, 2023
Presenter: Cailani Lemieux Mack, Faculty Sponsor: Kevin Angstadt, Department: Computer Science
“Improving Autonomous Vehicle Security with Redundant Computers”
Abstract: As our reliance on autonomous vehicles increases, security vulnerabilities and software defects threaten the successful completion of tasks and missions. An attacker could remotely compromise the control software running on the computer. Additionally, any software faults or hardware defects that are present can cause the computer to malfunction. To prevent mission failure, it is desirable to provide trusted and resilient operation in the face of defects and attacks.
In this talk, I will present a new platform for small autonomous vehicles that supports resilient and trustworthy operation with seamless recovery from primary control software failure. This platform utilizes a redundant, secondary, controller that can take over when the primary controller fails. We build on previous work that automatically repairs the control software to remove the bug or vulnerability. Our key contribution is the ability to seamlessly restart the primary control software post repair while the vehicle is in motion by transplanting sensor data between onboard computers. Our approach allows for successful initialization while in motion, reduces initialization time by 40%, and is robust to variances in sensor readings.

Presenter: Charles Reinhardt, Faculty Sponsor: Kevin Angstadt, Department: Computer Science
“Developing a Visual Studio Code Language Support Extension for the Snail Programming Language”
Abstract: A high quality programming environment (often an Integrated development environment or IDE) can be vital to enhancing developer productivity. Visual Studio Code (VS Code) is a popular, open-source text editor maintained by Microsoft [2]. VS Code delivers language-specific features through freely downloadable, community-built extensions on an online marketplace. Many of these extensions allow developers to take advantage of editing features such as syntax highlighting, code-autocompletion, or debugging support. The snail language (Strings Numbers Arrays and Inheritance Language) is a simple, object-oriented programming language meant to be implemented in a one-semester undergraduate course [1]. I present my experience in developing a VS Code extension to provide language support for the snail language. The extension implements support for syntax highlighting, rudimentary auto-completion, and dynamic error-checking diagnostics using VS Code’s Language Server Protocol (LSP) [3]. First, I give an overview of the contents of a VS Code extension. Next, I walk through how a VS Code extension runs, particularly highlighting the functions of VS Code’s Language Server Protocol. I will also discuss how this extension can be further developed to make use of VS Code's Debug Adapter Protocol to implement a debugger that supports breakpoints, start and stop behavior, and variable inspection [4]. Then, I discuss good software development practices including version control and documentation. Finally, I investigate the process of publishing a VS Code extension on the public extension marketplace.
References
[1] Kevin Angstadt. 2022. Strings Numbers Arrays and Inheritance Language (snail). Retrieved from https://snail-language.github.io/
[2] Microsoft. 2022. Visual Studio Code. Retrieved from https://code.visualstudio.com/
[3] Microsoft. 2022. Official page for Language Server Protocol. Retrieved from https://microsoft.github.io/language-server-protocol/
[4] Microsoft. 2022. Official page for Debug Adapter Protocol. Retrieved from https://microsoft.github.io/debug-adapter-protocol/

Presenter: Cody Bryan, Faculty Sponsor: Kevin Angstadt, Department: Computer Science
“Fractal Voyager: A Web Application for Exploring and Studying Complex Dynamics”
Abstract: Complex dynamics is a field of mathematics which studies the behavior of iterated functions in the complex plane. The complex plane is the set of all numbers that have a real part and an imaginary part, so they can include the imaginary unit i, which is the square root of -1. Applying an iterated function to numbers in the complex plane often produces extraordinary two-dimensional fractals. These images are crucial to the study of complex dynamics, as is interacting with the fractals and changing how they are generated to best understand complex numbers and functions. Existing software available to generate these fractals either supports limited features or is incompatible with modern operating systems.
We present Fractal Voyager, a web application to generate fractals based on custom scripts entered by the user that represent iterated functions. The application takes scripts written in a custom complex dynamics language, and converts them into code that can be run to create fractal images. Along with generating fractals, the web app provides the ability for users to interact with a fractal in ways such as: editing parameters, exploring the fractal (zooming and panning), and generating other fractals based on iterated functions that are related to the initial function. Fractal Voyager takes advantage of Web Assembly, which allows for the computationally intensive task of generating fractals to outperform pure JavaScript, the default language of the web. The application will allow mathematicians studying complex dynamics to research a wide variety of fractals conveniently on the web and can be a useful learning tool in teaching complex dynamics.
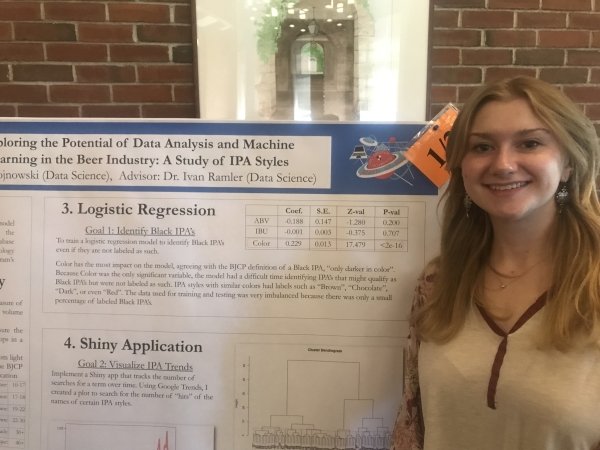
Presenter: Katie Wojnowski, Faculty Sponsor: Ivan Ramler, Department: Data Science
“ Exploring the Potential of Data Analysis and Machine Learning in the Beer Industry: A Study of IPA Styles”
Abstract: This study involved the analysis of beer data from various sources, including homebrew recipes and commercial beers. First a logistic regression model was developed to predict if a homebrew recipe was a Black India Pale Ale (IPA) even if not explicitly named as such. An R Shiny Web App was created to interface with Google Trends API to track the popularity of different IPA styles (e.g. Hazy IPA vs Black IPA). Additionally, this app shows a prototype for a beer recommendation system using machine learning techniques. This research sheds light on the potential of data analysis and machine learning in the beer industry, and may have implications for future product development and marketing strategies.

Presenter: Cassie Richter, Faculty Sponsor: Michael Schuckers, Department: Data Science
“Creating an R-Package for Biometric Authentication Functions”
Abstract: In this project, I constructed an R package based upon the statistical procedures in Prof. Schuckers Computational Methods for Biometrics Authentication, Springer (2010). We created a package containing functions for False Match Rate and False Non-Match Rate, 37 in total, with 12 datasets documented and used to demonstrate use. This project discusses how to create an R package with properly named functions, detailed documentation, and examples using data.

Presenter: Shane Hauck, Faculty Sponsor: Michael Schuckers, Department: Data Science
“Analyzing NFL Draft Prospects: Predicting Career Success with College Football and Imputed NFL Combine Data”
Abstract: This project aims to predict the potential success of NFL players' careers using a combination of NFL combine data and previous college football statistics, focusing exclusively on data collected prior to a player's draft. The NFL combine data provides information on players' physical attributes and abilities, such as speed, strength, and agility, while college football statistics offer insight into players' performance on the field during their college careers. However, accurately predicting a player's future success can be challenging due to missing values in the NFL combine data. To address this issue, the project employs data imputation techniques to fill in the missing values, enabling more accurate predictions. This research has the potential to help NFL teams make more informed decisions when drafting players, based on their performance in college and the NFL combine results, in order to predict their future success in the league.
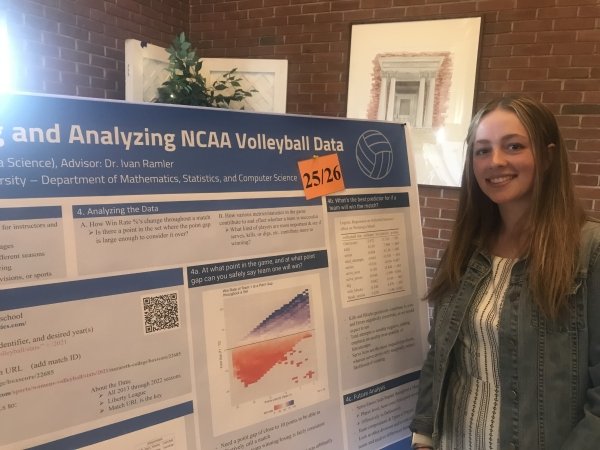
Presenter: Cassie Richter, Faculty Sponsor: Ivan Ramler, Department: Data Science
“NCAA Volleyball Data Collection and Analysis”
Abstract: This presentation discusses how to collect and store NCAA Sports Data in a way that makes it more accessible for researchers and instructors. Using ECAC Division 3 Volleyball data, this talk will demonstrate effective scraping in R and how to efficiently store multiple tables into a relational database. Finally, we will show sample statistical analyses that make use of different features of the match and team data in order to visualize and investigate win percentages.

Presenter: Alexandra Hill, Faculty Sponsor: Dan Look, Department: Mathematics
“The Interaction Between Mental Health and Positionality in Literature: A Data Science Analysis”
Abstract: Mental illness representation is a vital issue in literature, both reflecting current societal norms and influencing contemporary social opinions. Does the portrayal of mental health vary in different social groups -- specifically based on gender, race, and the intersectionality of the two?
The traditional way to analyze literature is via close reading, carefully reading a limited number of novels and analyzing the smaller details of the writing. However, a new practice called distance reading has arisen with new technological advances. Through distance reading, one can analyze a large number of pieces of literature, utilizing data science techniques to numerically analyze the text, create visualizations, and essentially view the myriad writings from a broader perspective, allowing the discovery of overarching patterns.
Using 41 YA fiction novels published after 2000 that revolve around a mentally ill protagonist, I explored the portrayal of mental health -- the diction, sentiment, and topics -- and whether any patterns arise when comparing the novels based on positionality, looking at both the positionality of the authors and the protagonists. From this exploration, I analyzed the current state of mental health portrayal in literature and the broader implication for mental health representation, especially for minoritized communities.
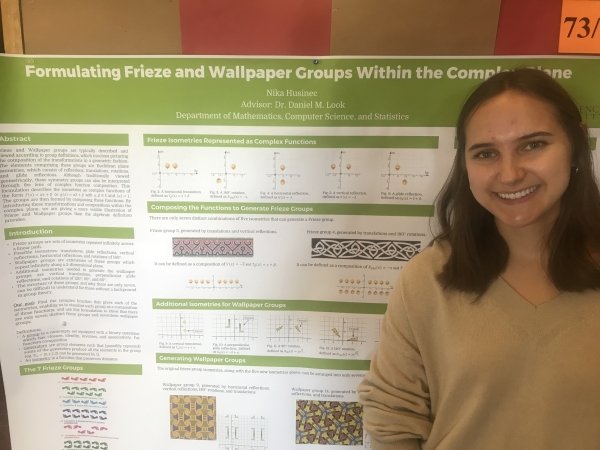
Presenter: Nika Husinec, Faculty Sponsor: Daniel M. Look, Department: Mathematics
“Formulating Frieze and Wallpaper Groups in the Complex Plane”
Abstract: Frieze and Wallpaper groups are typically described and viewed according to abstract algebra, which involves picturing the transformations’ compositions in a primarily geometric fashion. The elements comprising this group are Euclidean plane isometries, which consist of reflections, translations, rotations, and glide reflections. Although traditionally viewed geometrically, these symmetry groups can also be interpreted through the lens of complex function composition. This formulation describes the isometries as complex functions of the form f(z)=αz+β or g(z)=α¯z+β with β∈R, α∈C , and |α|=1. By introducing these transformations and compositions within the complex plane, we are giving a more visible illustration of Frieze and Wallpaper group elements than the algebraic definition provides.

Presenter: Jane Baumer, Faculty Sponsor: Michael Schuckers, Department: Statistics
“Calling All Saints Program Anaylsis”
Abstract: The Calling All Saints Program has been fundraising for the St. Lawrence University annual fund for over a decade. This project constructs statistical models to look at the leading factors that contribute to the likelihood of a donation through the Calling All Saints (CAS) program. Utilizing data from the past ten years, we looked at all CAS and non-CAS gifts. We fit logistic regression and lasso regression models to explain trends and predict outcomes. The goal of the analysis is to use statistical methods to provide evidence for strategic improvements in outreach for the Calling All Saints program, and to influence the program beneficially.
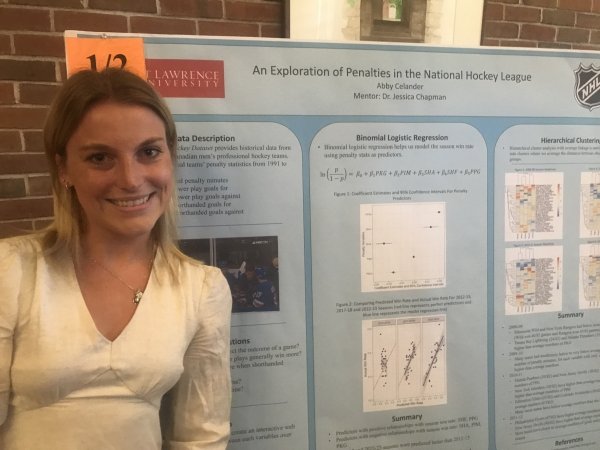
Presenter: Abby Celander, Faculty Sponsor: Jessica Chapman, Department: Statistics
“An Exploration of Penalties in the National Hockey League”
Abstract: As in any sport, ice hockey pertains to a set of rules that, if broken, come with a consequence. Penalties in ice hockey are different from many sports though, in that when a player gets called on a penalty, they spend a certain amount of time off the ice and their team plays with a player down for that time. With ice hockey being only five-on-five (not including the goal tender), a time frame where a team is down a whole player would seem like it would cause a major disadvantage to the shorthanded team and advantage to the team with all five on the ice.
The Professional Hockey Dataset taken from Kaggle contains team-level penalty statistics, including penalty minutes (PIM), shorthanded goals for (SHF), shorthanded goals against (SHA), power play goals (PPG), and power play goals against (PKG). We explore these data with binomial logistic regression and hierarchical clustering.

Presenter: Caleb Hamblen, Faculty Sponsor: Robin Lock, Department: Statistics
“Alternatives to Statistical Power that Avoid “p < .05””
Abstract: Traditional power assesses how often we reject a null hypothesis for a particular value of the parameter. One drawback of this approach is that the “rejection” decision depends on a specific significance level like 5% which has recently become controversial. Our goal is to develop alternative measures that can compare the effectiveness of statistical tests without relying on a fixed significance level. We do this by considering the entire distribution of possible p-values for any value of the parameter. If the alternative hypothesis is true, we prefer a test which tends to have smaller p-values. For example, we define a quantity called Dpower which takes values from -1 to 1, where values closer to 1 indicate more effective tests for a specific alternative parameter.

Presenter: Edward Smith, Faculty Sponsor: Ivan Ramler, Department: Statistics
“Dissimilarity Metrics for Probability Distributions with an Application in Music Artist Classification”
Abstract: In this project, we explore methods of measuring dissimilarity between probability distributions, with an application to music data. We use multivariate normal distributions to represent musical artist’s style and calculate dissimilarity between artist’s style for the purpose of hierarchical clustering. The metrics we explore in this project are the Euclidean distance, Bhattacharyya Distance, K-L Divergence and Hellinger Squared distance. When applied to the music data, the Hellinger Squared and Bhattacharya Distances performed similarly, and the K-L Divergence gave less desirable results.